Home › Forums › Destiny of an Emperor › DoaEd text-editing edition (Alpha 0.04 released 7/07/08)
- This topic has 131 replies, 10 voices, and was last updated 14 years, 6 months ago by
sonic.penguin.
-
AuthorPosts
-
April 27, 2008 at 5:05 pm #34539
Niahak
ModeratorJames, I’m looking through the source code you sent me and I’ve got a question or two.
First off, how do you tell the difference between values you’ve already converted and unindexed letters?
Say you have
Hi, Liu Bei!
After converting officers, you have
Hi,B2A6!
Or am I missing something?
I was thinking about this last night and my approach may be recursive. I’m looking at something like
string convert_line(string line)
string hex = convert_largest_section(line);
return convert_line(stuff_before_hex) + hex + convert_line(stuff_after_hex)
I’ll have to find a way to get the index where I’m converting but I’m sure I’ll be able to grab it somehow.
April 27, 2008 at 6:55 pm #34540Xian Zhu Xuande
ParticipantIf I recall correctly, I used special characters.
So:
Hi, Liu Bei!
Becomes:
Hi,%B%2%A%6!
In my program I used different special characters for different types of conversions. This allowed me, later, to scan through the text and wrap different times of replacement with different types of span tags, thus giving the user feedback as to what their text actually turned into (so they know where they can change words to trim their script).
When you are swapping out any remnants on a character-by-character basis you will have to be careful because a normal match would get your flagged characters. What you do in this case is use a regular expression to make sure there is no special character behind the letter you are replacing. So replacing ‘A’ in the hex might look like this:
Find: ‘/(?<![%$#])(A)/i’
Replace: ’10’
This would be your last replacement so there is no real need to place flags. There’s no real need to span (or wrap — whatever you would do in your program) as it can be displayed in the default color.
Regular expressions are a little different for each language. Here is a breakdown of the regular expression shown above:
‘/(?<![%$#])(A)/i‘
String Container.
‘/(?<![%$#])(A)/i’
Delimiter. This shows your expression where it starts and ends. Usually your language can use a variety of delimiters. The delimiter cannot appear in the regular expression itself. In HTML I almost always use ‘#’. If you are using something like curly braces the first opens { and the last closes }. If something else the same character opens and closes.
‘/(?<![%$#])(A)/i’
This is the value we are capturing. By placing it in parenthesis we are storing it for later reference. We won’t be referencing it, though. Sometimes you have to capture the text you want to replace. In this case we will be replacing it. By placing it in parenthesis you know it will work (though you can check your language’s documentation).
‘/(?<![%$#])(A)/i’
This is a lookbehind. (?< means match behind is, ?<! means match behind is not). (<![…]) means look behind the following value (in this case (A)) to make sure x (in this case [%$#]) does not match. Values in brackets [%$#] are characters we are looking for. Rather than %$# you would list any flagged characters you have used up to this point. Please note that if any of these characters hold special meaning in your flavor of regular expressions you may have to flag them. Or they may be treated as plain text. $ is a good example ($ usually matches the end of a string) and may have to be written as "$" (without the quotes). Although parenthesis are used for a lookbehind nothing is actually stored, so you don’t need to worry about the contained text being altered.
‘/(?<![%$#])[/b]/i‘
This ‘i’ which appears after the closing delimiter is usually a letter that modifies the default handling of the regular expression. This is just an example and actually would not work the way we want in PHP (which uses Perl regular expressions). ‘i’ tells the string it is case insensitive. Default is case sensitive, which is what we would want. Your language may be different and you just need to know that this exists. You may specify it as an argument for a function instead.
– – – – – – – – – – – –
When you are done, simply strip out all the special characters from your script! That you can do with a simple regular expression or with a series of find/replaces. Either way works just fine.
May 10, 2008 at 12:37 am #34541ModeratorJust wanted to post here to say that some progress has been made.
I’ve been working on exporting a script to hex. RegEx has helped a bunch, but I’ve hit a snag so I’m going to ruminate on it while playing some P3:FES or something.
snag: I’m pulling hex tables into a hash table and matching them. Unfortunately, since I’m not guaranteed that they’re in the order I put them, I need to figure out a nice way to sort them by length (generally).
Problem illustration: we have "There", "The", and "here" and we want to match "There’s". I want to make it so that "There" is always the first one checked – if we substitute in "here" then we’re wasting a character, and "The" wastes 2.
(this isn’t really too hard a problem – I’m really just sort of lazy :P)
Hope to have something more concrete to show by the end of the weekend.
May 10, 2008 at 7:44 pm #34542ParticipantNiahak said:
Problem illustration: we have "There", "The", and "here" and we want to match "There’s". I want to make it so that "There" is always the first one checked – if we substitute in "here" then we’re wasting a character, and "The" wastes 2.
I already solved that problem in my code. Steal it.
There’s a massive find/replace table at the top of the PHP document. Every word is sorted in such a way that you will not encounter any conflicts. Used along with flags to make sure text isn’t affected multiple times (or some other method) you won’t have to worry about it. Adapt it, hard code it in, and sleep easily tonight. :)
May 11, 2008 at 8:20 pm #34543ModeratorI figured out another way around the problem.
Still not usable. I’m having problems getting my values to match up with those in the ROM. I’m about 60 characters off for the total script (not really too bad, all told :P).
This yields some interesting behavior.
When Song Ren and Song Yong join you, they say "Castle, home of Tao Qian". When you turn them down, they lecture you on how you need to equip your weapons.
When you talk to the "Cui Zhouping is never home" guy, he gives you 200 gold and 1000 rations – each time!
And, of course, the most interesting so far:
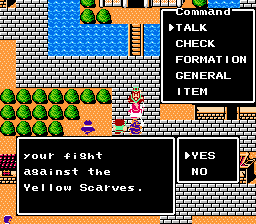
Hmm, Xuzhou townsperson wants to join up. What could possibly go wrong?
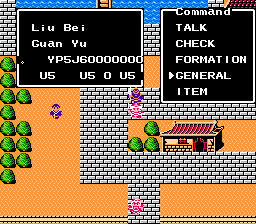
…Oh.
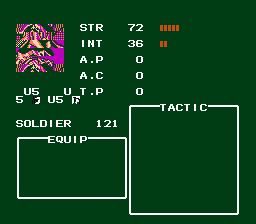
…Touche.
So no release yet, but I’m getting closer.
May 12, 2008 at 4:15 am #34544ParticipantHaha… I encountered entertaining problems like this while I was experimenting with moving text around or taking up extra space. And then more like it when I was experimenting with events and L
May 16, 2008 at 10:41 pm #34545ModeratorAnother update, as I’ve done my Friday now-routine leave-work-early-to-do-DoaEText:
I have found a few more special tags for item types, officer types, etc. They’re not terribly interesting, just placeholders for "item-in-chest" or "officer-next-to-me" (Song Ren/Song Yong are the only ones who seem to use this which is just annoying).
You can even refer to items in-text: in practice this is only used for the Gemsword and (I think) Chi Tu Ma. I didn’t bother implementing it as a dictionary pattern because it would be annoying to make yet another simple table.
I have, I *think*, a properly generated block of text. But there remains one problem, and it’s a good problem to have: my generated text takes up less space than the original by a couple dozen characters.
While this is nice and all, I haven’t implemented pointer updating so I can’t test in-game and expect decent results yet. Likewise, I can’t ad-hoc test by opening, saving, then opening again (since I load using said pointers, this only succeeds in horribly breaking things).
I’m hoping to put together a pointer-updating algorithm sometime this weekend. If I get a chance and the motivation, I may go so far as to implement line-saving, which would result in a passable beta. Which means there could be a release sometime this weekend.
May 17, 2008 at 8:00 am #34546ParticipantSexy news, Niahak.
Regarding the code used in scripts… they do some really screwy things but they don’t usually mess up so badly that you wind up gaining characters after the conversion. You might want to double-check that. There are some blocks of text which are not abbreviated at all. But I’m not sure if that is because they can’t be abbreviated or if it is because they didn’t bother for some reason.
I mapped the items back when I was working on this. I’m not sure I bothered with their implementation in my own translation table (and my reasoning was the same as yours).
May 18, 2008 at 9:53 pm #34547ModeratorXian Zhu Xuande said:
Regarding the code used in scripts… they do some really screwy things but they don’t usually mess up so badly that you wind up gaining characters after the conversion. You might want to double-check that. There are some blocks of text which are not abbreviated at all. But I’m not sure if that is because they can’t be abbreviated or if it is because they didn’t bother for some reason.
I’m still not sure whether this is the case. The stuff I seem to be gaining from is usually:
word|
where word is in the dictionary, but the dictionary code did not include |
Or some screwy stuff from the original, like Lu Su/n.
For now I have made it so that a given line updates when a) you choose another line or b) you save the ROM and it is the currently open line.
This means if a line isn’t changed, it isn’t updated – this is essentially a safeguard, so this re-do-over of the original text isn’t done on-load or even on-save unless you modified (or scrolled over) the text. Even without the compression, there are 200 free bytes – so the text in there can be somewhat expanded, although don’t expect much.
That said, I’ve done this "compression" and tested through most of the YT chapter (which contains the last line in the ROM, incidentally) and all lines were okay. I also ran a test where I changed some dialogue:
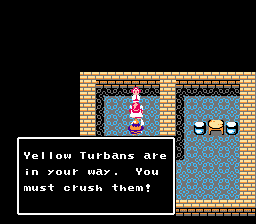
Everything seems to be working, so I hereby declare the alpha release of DoaTextEd.
Please download it from here.
This probably does not work 100%! Please do test it with some example text you might use. Save often, and in different files.
There are a lot of control codes and such in here; for example, [OFFICER], [ITEM], etc.
I do not recommend changing this section of the text. The text is mostly in order of YT->DZ->YSs etc, and starts a ways down with the initial lines.
If there is a reference such as [OFFICER] in a given block of text, it’s not recommended to change it or remove it. I’m not sure what it’ll do; it’s very possible these lines are somehow "given" a current officer and therefore this could cause some strange things.
If you get a crash, please post about it and any info you might have. Right now, there is a textbox reserved for the HEX actually written to ROM; this is a debugging tool and will probably be removed before long, but it may be useful for now.
If you see "Hex is different: " with a little string of bytes, but the text didn’t change, don’t worry about it (unless of course, it’s wildly different – different lengths, for example, may be notable).
May 19, 2008 at 3:26 am #34548ParticipantThe officer references aren’t too complicated. The only confusing thing about them is that there are a handful. There is one, for example, that references your party leader. There is another, I believe, that references the opposing party leader. Maybe you can display them as [OFFICER-F6] or whatever. Give the program the ability to recognize that and thus trigger the officer flag. That way people can see which officer reference is used in a block of text and move it as appropriate?
May 19, 2008 at 4:38 am #34549ModeratorI already have separate references for each type (they have to be completely unique), though right now they’re just [OFFICER], [OFFICER-2], etc. (I think there may be [OFFICER-TARGET] or something).
Oh, another note of caution: This program does not make sure your input will be less than 18 characters long, so be careful not to step out of those bounds. That’ll probably be among the first things I add to the next version
(Stuff like officer references shouldn’t be too bad, since I can just assume they’re the max length).
May 19, 2008 at 5:39 am #34550Lord Yuan Shu
Keymasterhaha damn this is awesome, I’m going to have to take a look at this sometime soon.
Welcome to Lord Yuan Shu Walkthrough Guides ·
Huo Hu's Adventure started Destiny of an Emperor hackingMay 19, 2008 at 3:21 pm #34551ParticipantDo you allow the user to specify where the next line takes place? It would probably be best to allow that capability (sort of like I do in my tool) and punish them if they are incompetent by allowing characters to spill over. With some extra effort you could both allow it and validate as well. :)
I would hate to see something like ‘Lu Bu’ on a single line. :shock:
May 19, 2008 at 10:16 pm #34552ModeratorYeah, it’s a simple text box just like the ones used in this forum. A new line is just replaced with a new line in the relevant dialogue.
May 20, 2008 at 10:03 pm #34553Fallout
Participantfinally!! thanks a million, niahak! i have a lot of work to do…
-
AuthorPosts
- You must be logged in to reply to this topic.